智慧醫療輿情助理
114a期末專案「生成式ai」選題動機: 因目前任職於花蓮慈濟醫院公共傳播室,日常工作涉及大量醫療衛教新聞的監測、官網內容維護以及針對網路健康議題的輿情分析。傳統人工搜集與篩選方式耗時且難以即時覆蓋所有資訊源。希望透過利用生成式 AI 技術,建構一套「人機協作」的智慧輔助工具,加速新聞篩選與文案產出的流程。
一、使用模型
我選擇使用 Groq 平台搭配 Llama 3.1 8B Instant 模型,原因如下:
- 推理速度 (Speed / Low Latency)
- 專案應用:對於「新聞監測與分析」場景,特別是「Batch Scan (批量掃描)」功能,速度至關重要。使用 Groq可以讓使用者在輸入多個網址後,幾乎「即時」看到分析結果,而不需要像使用 GPT-4 或舊版 Gemini 那樣等待許久。
- 高性價比 (Cost-Efficiency)
- 模型大小:程式碼中選用的 llama-3.1-8b-instant 屬於 80 億參數的輕量級模型。相比於 70B 或 400B 的大模型,它的運算成本低得多。
- API 成本:Groq 目前提供非常具競爭力的價格(甚至包含高額度的免費層級),這對於需要頻繁呼叫 API 進行「初步篩選(analyze_relevance_only)」的應用來說,能大幅降低營運成本。
- 足夠的任務能力 (Performance “Good Enough”)
- 摘要與分類:Llama 3.1 雖然是 8B 的小模型,但在 Meta 的訓練下,其閱讀理解、摘要生成和分類能力已經超越了許多上一代的 70B 模型。
- 適用性:對於判斷「這則新聞是否與慈濟醫院相關?」或是「撰寫 200 字摘要」這類任務,8B 模型的智力已經完全足夠。使用更大的模型(如 Claude 3.5 Sonnet 或 GPT-4o)雖然可能文筆更好,但在這種特定且規則明確的任務上,邊際效益很低,卻會犧牲速度。
- 長文本支援 (Context Window)
- 雖然 8B 模型較小,但 Llama 3.1 支援長達 128k 的 Context Window。即便 Groq 有時會對上下文長度有限制(通常至少 8k 或更多),這對於處理一般新聞文章(通常在 1000-3000字之間)來說已經綽綽有餘,不需要過度擔心文章被截斷的問題。
所以我選用 Groq + Llama 3.1 8B 是一個「速度優先、成本優化」的考量。它讓「新聞篩選助手」能夠像搜尋引擎一樣快速反應,而不是像傳統 AI 聊天機器人那樣慢條斯理。
二、專案目的
這個專案(Healthcare Insight Agent,花蓮慈濟醫院 AI 新聞監測系統)的主要目的,是透過 AI 自動化技術,解決公傳室與決策層面臨的資訊過載 (Information Overload)問題,並提升輿情反應的速度與精準度。 具體來說,此專案旨在達成以下三個核心目標:
- 提升資訊篩選效率 (Efficiency)
- 現狀痛點:人工每天手動瀏覽大量新聞網站、RSS 訂閱源或搜尋引擎結果,不僅耗時費力,且容易因疲勞而遺漏重要訊息。
- 突破點:利用自動化爬蟲 (Crawler) 與 AI 語言模型 (LLM) 進行7x24小時的即時監測與初步篩選。系統能在一分鐘內過濾數十甚至上百篇新聞,快速剔除廣告與無關內容,只將真正相關的「高價值資訊」呈現在使用者面前。
- 精準判讀與風險預警 (Accuracy & Risk Management)
- 現狀痛點:關鍵字搜尋(如「醫療」、「醫院」)往往會帶來大量雜訊(如一般健康廣告、其他醫院的例行新聞),且難以第一時間判斷該新聞對本院是「正面宣傳」還是「潛在危機」。
- 突破點:透過大型語言模型(Llama 3.1 /Gemini)進行深度語意分析,不僅是看關鍵字,更能理解文章脈絡。系統會自動為每則新聞打分數(相關性、緊急性、風險值),當偵測到高風險或高緊急性的負面輿情時,能提供預警依據,讓團隊能從「被動應對」轉為「主動管理」。
- 輔助決策與知識萃取 (Decision Support)
- 現狀痛點:即便篩選出相關新聞,要將長篇大論的文章轉化為內部決策用的簡報或報告,仍需大量人工撰寫摘要。
- 突破點:AI會自動生成結構化的繁體中文摘要以及具體的行動建議(如:建議轉發、建議澄清、建議持續關注)。這能大幅縮短從「接收訊息」到「採取行動」的時間差,讓專業人員能將精力集中在擬定策略,而非消耗在基礎的資訊整理上。
總結:此系統是為了打造一個全天候、高效率且具備判斷力的數位助手,協助花蓮慈濟醫院公傳團隊在海量資訊中,精準捕捉每一條對醫院形象與營運至關重要的情報。
三、專案重點
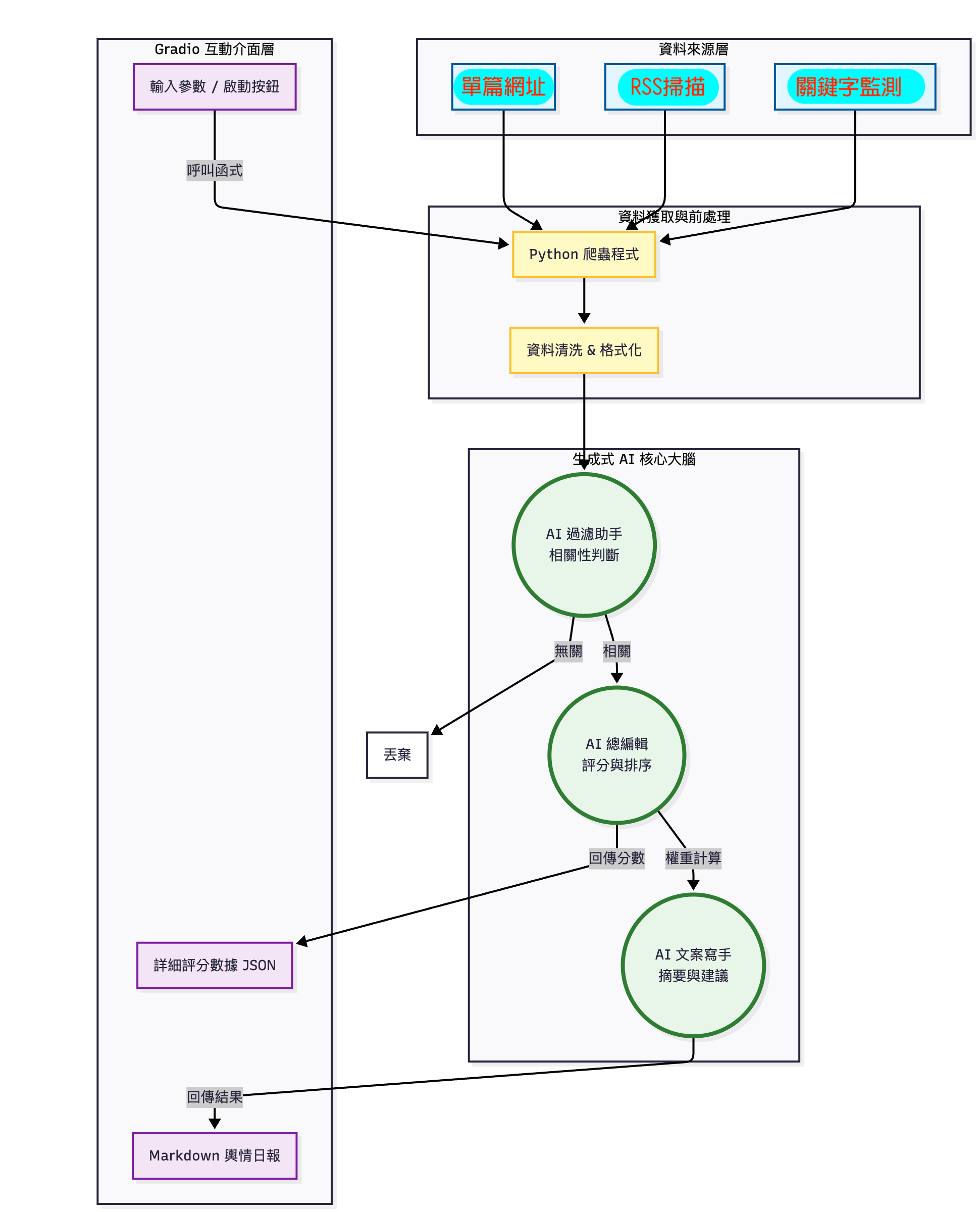
系統架構圖
執行流程 (Workflow):三個主要階段:
- 資料獲取 (Data Acquisition):
- 設計爬蟲 (Crawler) 抓取目標網站(如:健康新聞網、PTT/Dcard 醫療版、衛福部公告)。
- 使用者也可以手動輸入特定新聞連結進行分析。
- 智慧處理 (Generative AI Core):
- 過濾 (Filtering): 使用 LLM 判斷內容是否與「慈濟/花蓮/醫療」高度相關,剔除廣告雜訊。
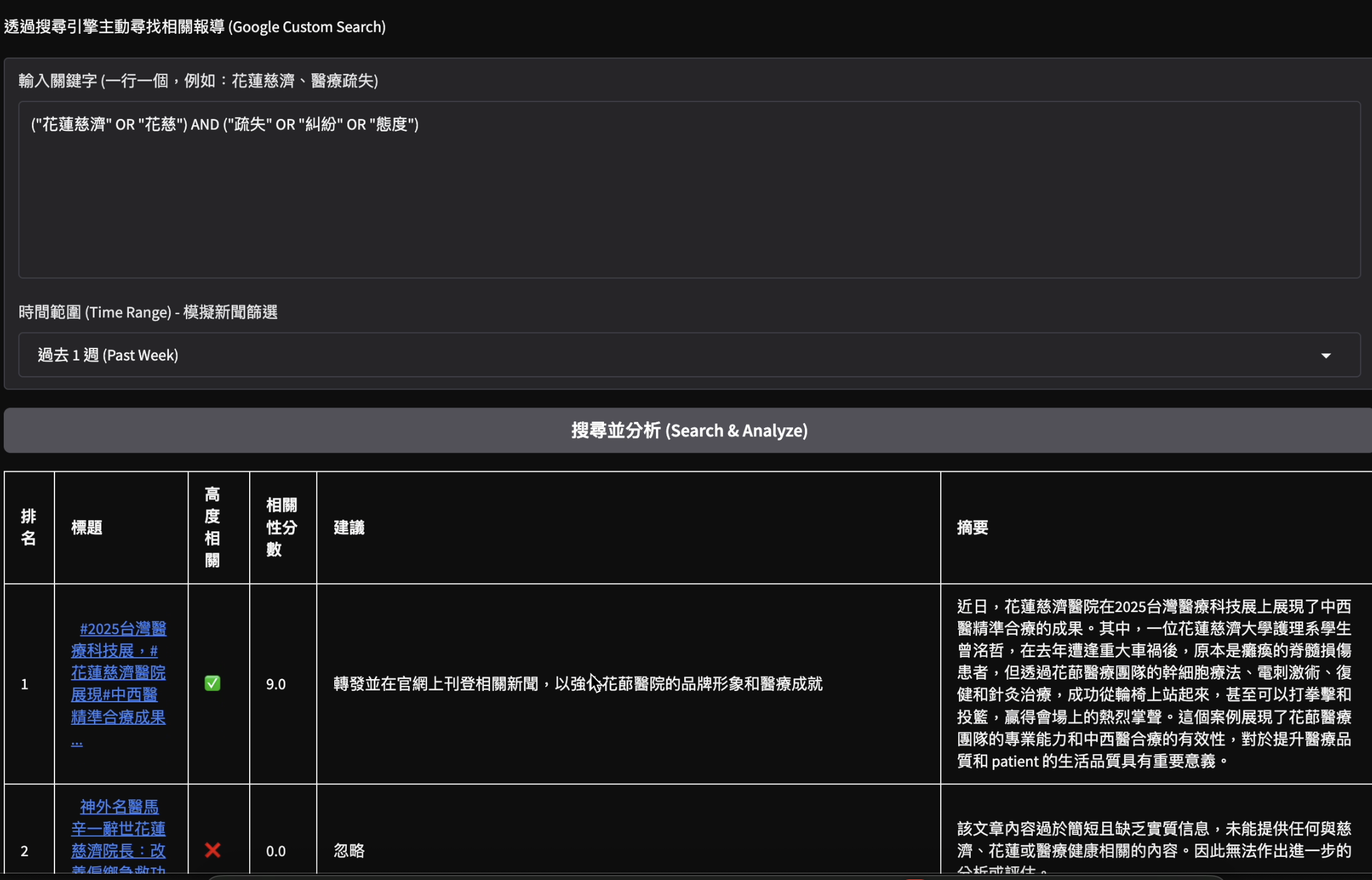
- 評分 (Ranking): 依據「關聯度」、「急迫性」、「輿情風險」三個維度進行權重打分 (1-10分)
- 生成 (Generation): 針對高分內容,自動撰寫 200 字摘要,並提供「公傳應對建議」(如:建議轉發、需澄清、僅供參考)。
- 互動介面 (Interactive Interface):
- 採用 Gradio 架構,建構 Web 操作介面。
- 提供 Markdown 格式的輿情日報,讓公傳室人員能一目了然並快速複製使用。
- 使用技術 (Tech Stack)
- 前端介面: Gradio
- 語言模型: llama-3.1-8b-instant
- 核心語言: Python
- 資料爬取: BeautifulSoup4, Selenium。
- Prompt Engineering: Chain-of-Thought (思維鏈) 讓 AI 解釋評分理由、Role-Playing (角色扮演) 模擬資深編輯視角。
用 Gradio 作為「互動介面」:使用者發出指令(Trigger),系統處理後回傳結構化的報告(Report)。
技術架構如下:
前端介面:使用 Gradio 建置互動式網頁介面。(完成後部署在Hugging Face上)
語言模型 (LLM):
- Groq (優先):使用模型:llama-3.1-8b-instant (以速度快且成本效益高著稱)。
- Google Gemini (備援):使用模型:gemini-2.5-flash
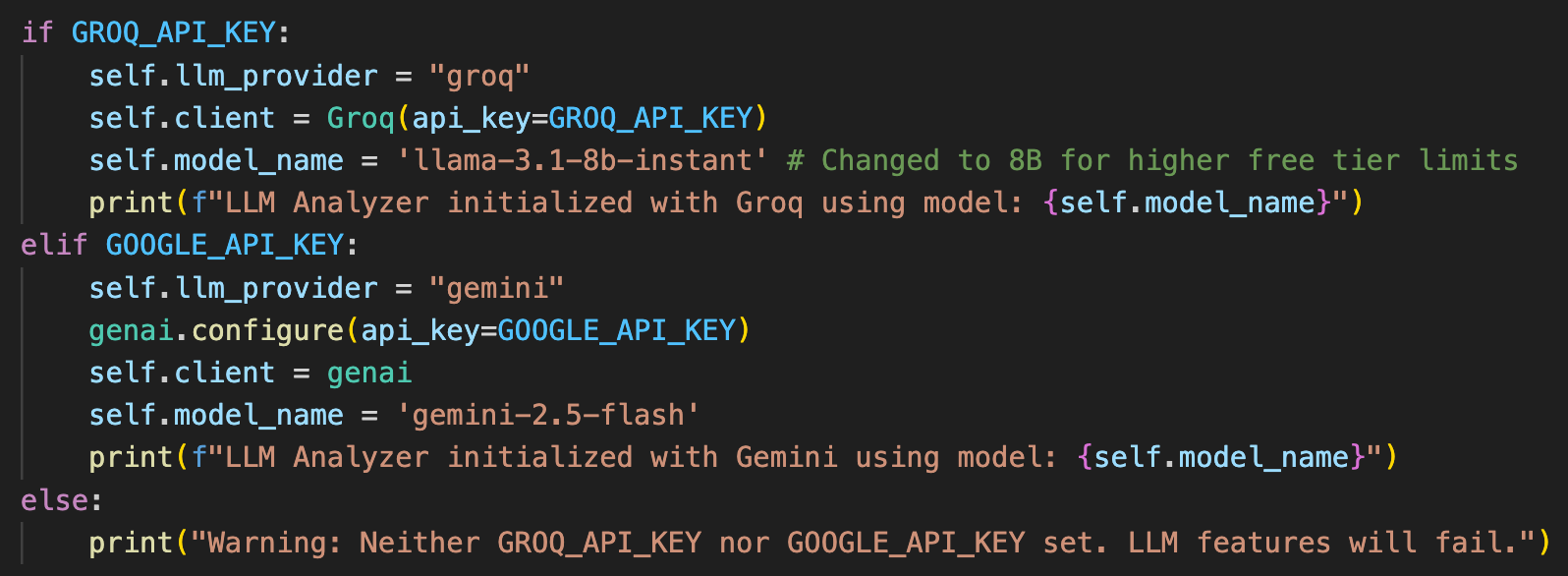
爬蟲與資料獲取:
- BeautifulSoup4 / Requests:用於抓取靜態網頁內容。
- 說明:這是抓取網頁內容的主要函式。它首先嘗試使用 requests.get() 下載網頁,然後利用 BeautifulSoup(response.text, ‘html.parser’) 解析 HTML並提取標題與內文。
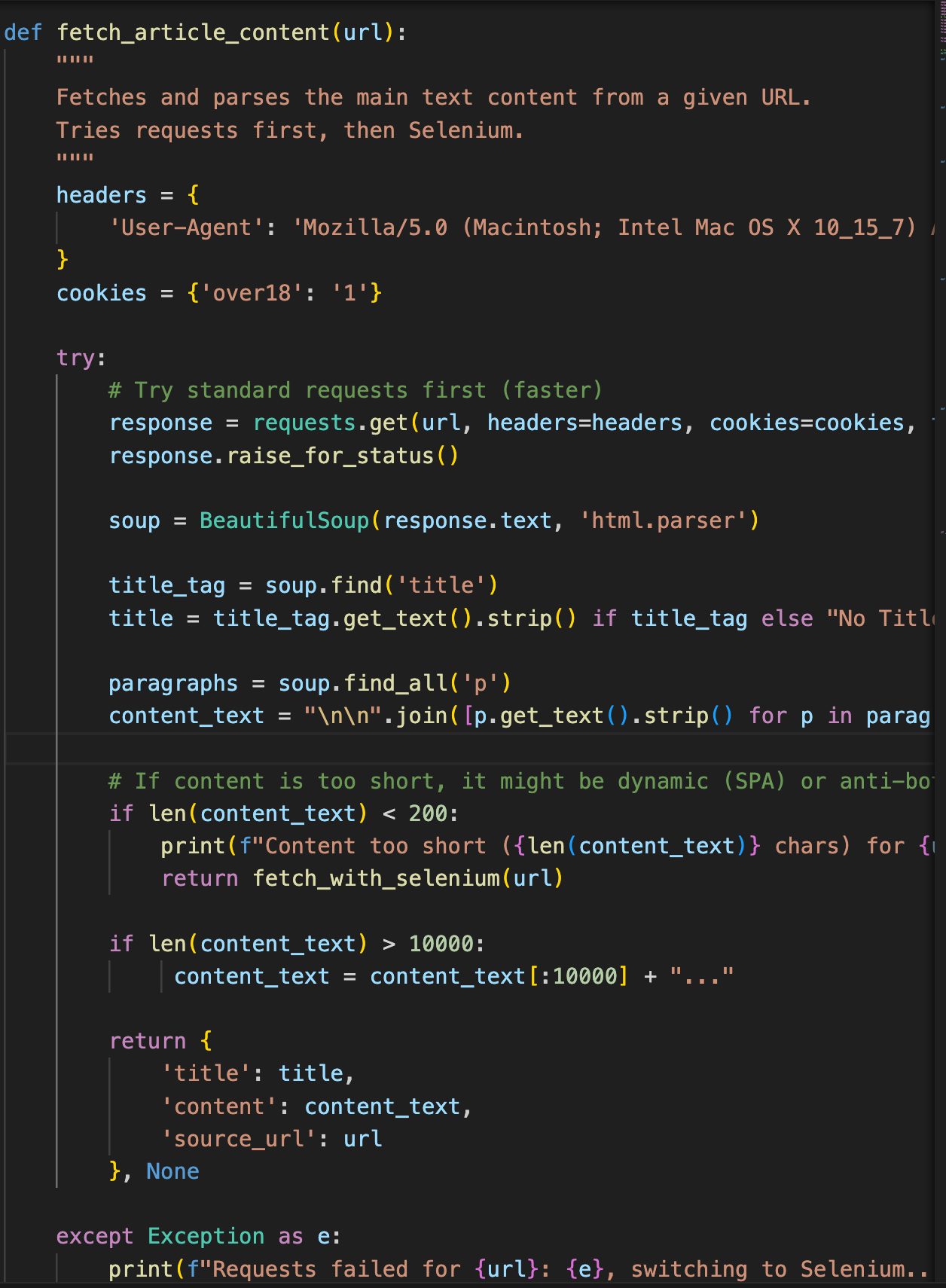
- 說明:這是抓取網頁內容的主要函式。它首先嘗試使用 requests.get() 下載網頁,然後利用 BeautifulSoup(response.text, ‘html.parser’) 解析 HTML並提取標題與內文。
- feedparser:用於處理 RSS 訂閱源。
- 說明:使用 feedparser.parse(rss_url) 來讀取 RSS 網址,並透過迴圈 (for entry in feed.entries) 提取文章的標題、連結與發布時間。
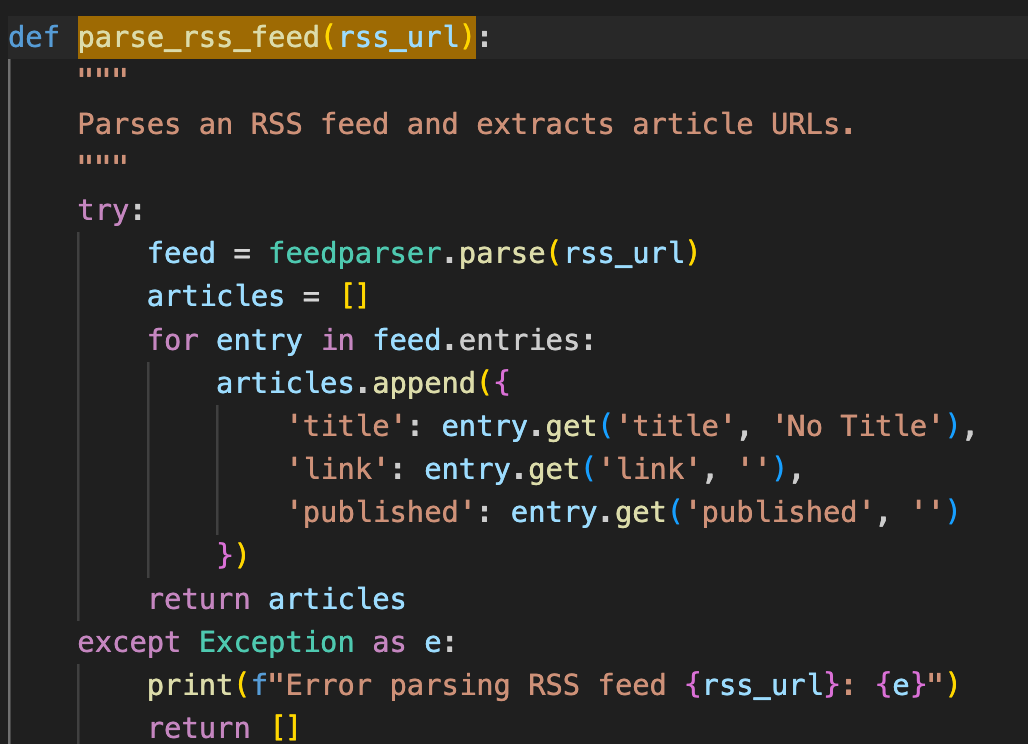
- 說明:使用 feedparser.parse(rss_url) 來讀取 RSS 網址,並透過迴圈 (for entry in feed.entries) 提取文章的標題、連結與發布時間。
- Google-search:用於搜尋相關新聞。
- 說明:使用 googleapiclient.discovery 套件
- selenium:列於依賴中,可能用於處理動態網頁。
- setup_selenium(): 負責初始化無頭 (Headless) Chrome 瀏覽器。
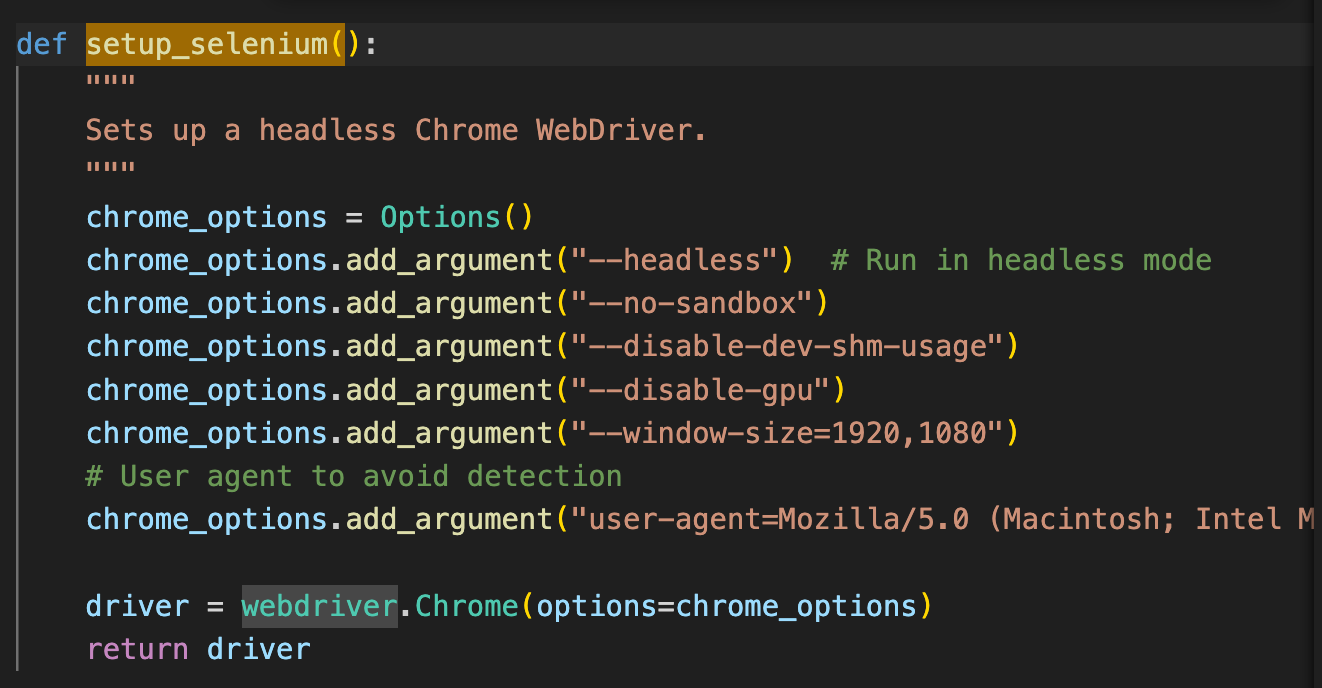
- fetch_with_selenium(url): 當靜態抓取失敗或內容過短(當網頁是用 JavaScript 動態生成的)時,程式會切換到此函式,模擬真實瀏覽器載入頁面並執行 JS,然後再抓取內容。
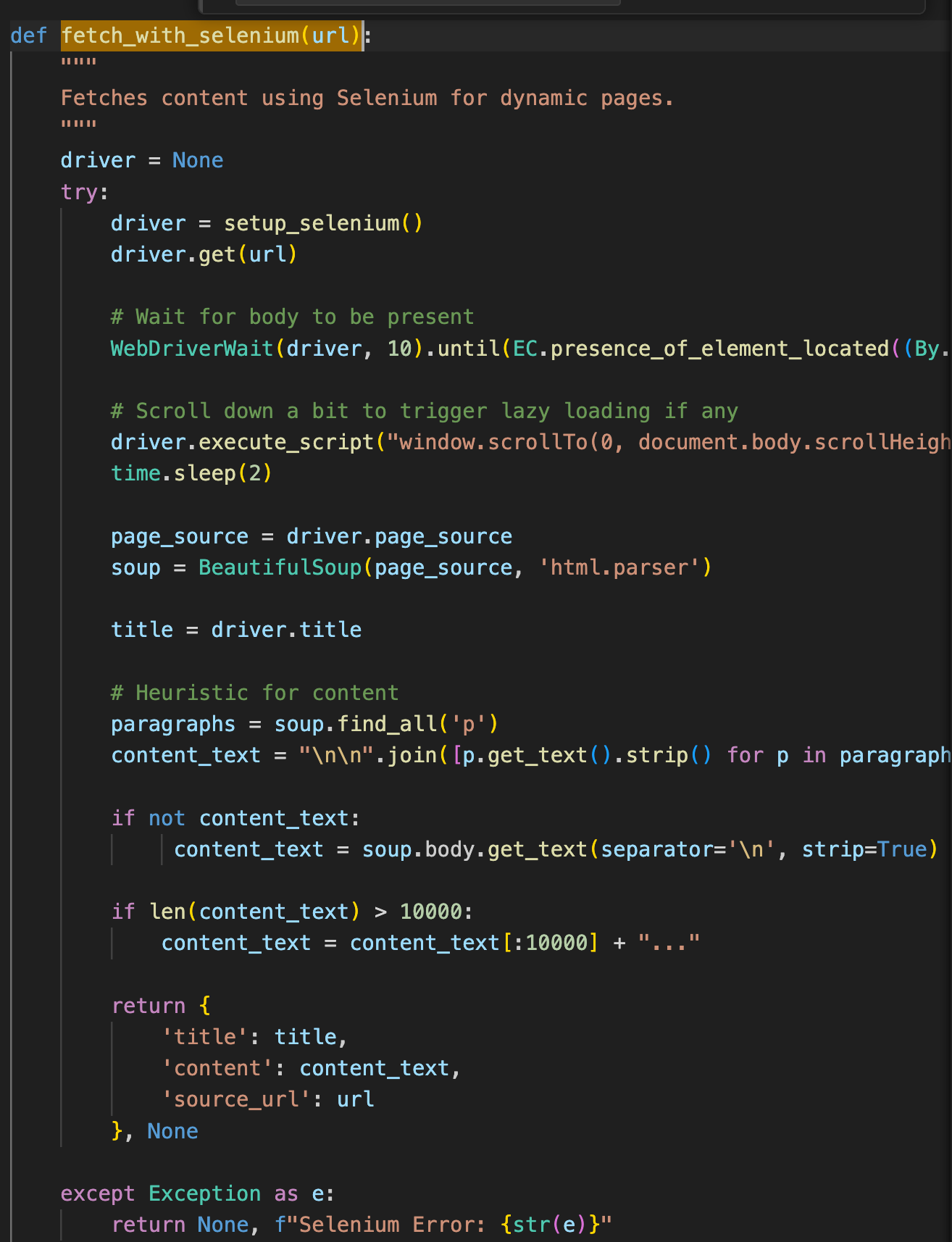
- setup_selenium(): 負責初始化無頭 (Headless) Chrome 瀏覽器。
四、最終成果。
系統網址:https://huggingface.co/spaces/petertsengtw/tzuchinews_ai
系統畫面如下
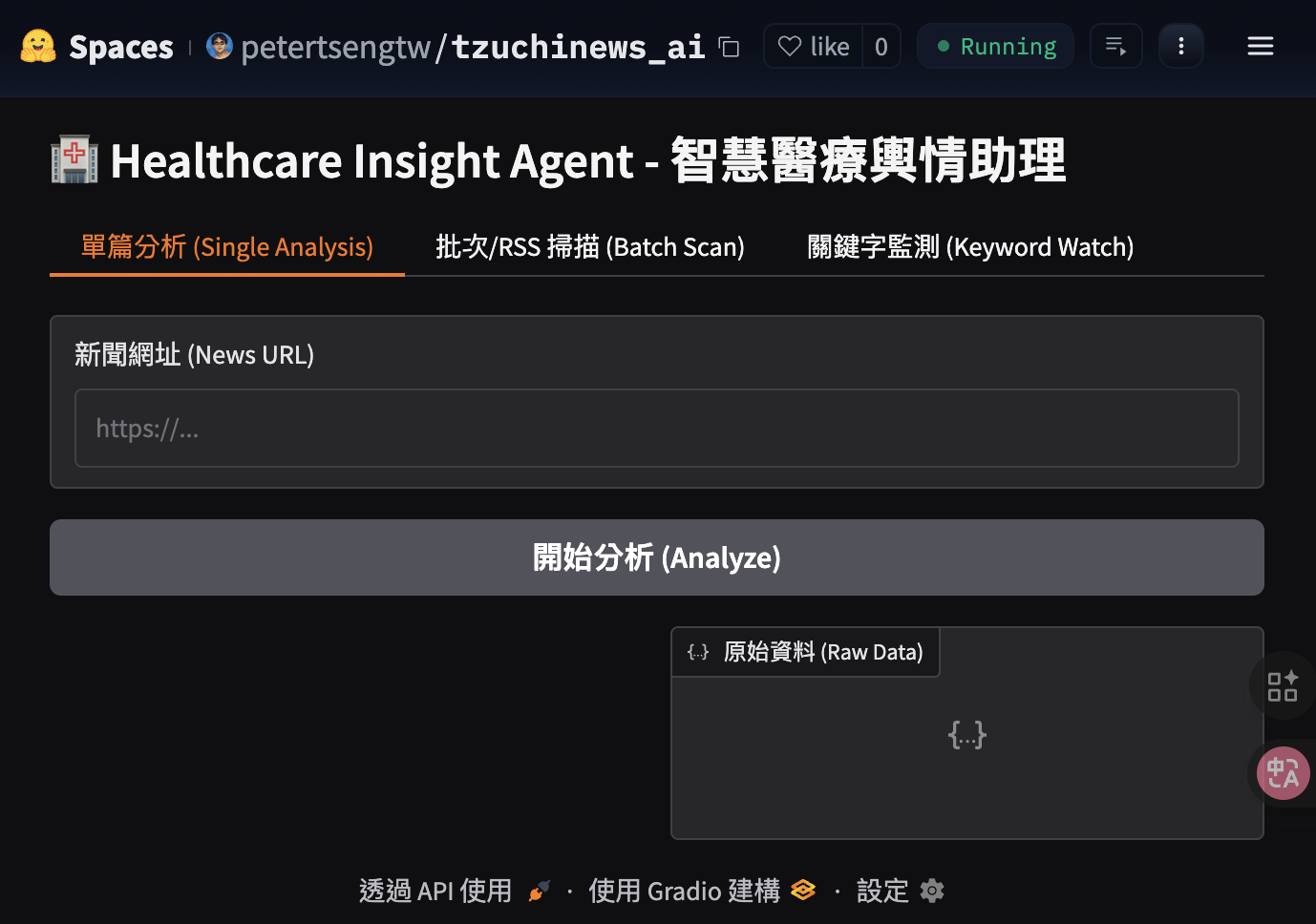
單篇網址分析(Single-Analysis)
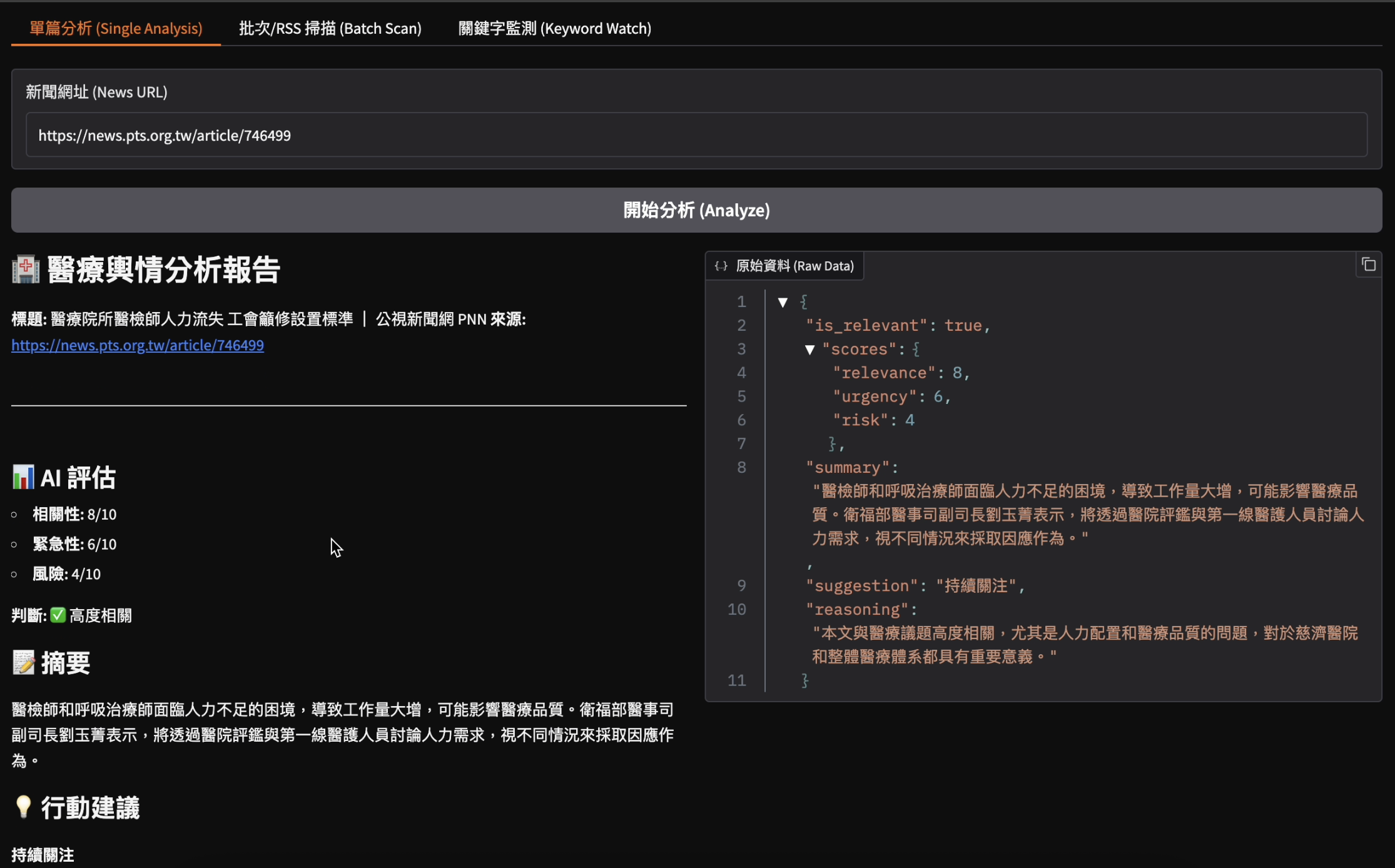
批次/RSS掃描(Batch Scan)
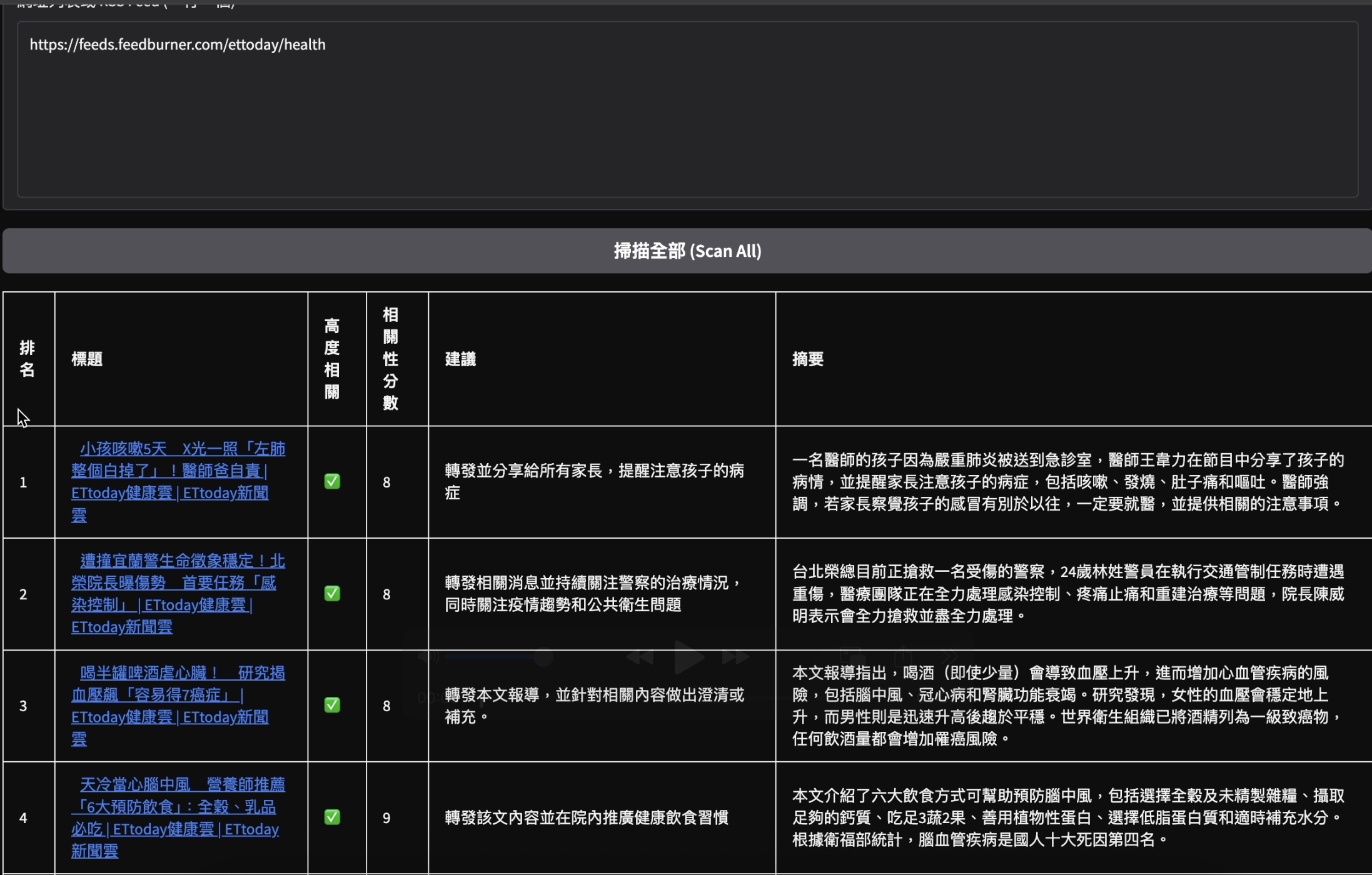
關鍵字監測(Keyword Watch)